Error-Correcting Codes: Hamming Distance
So-called linear codes create error-correction bits by combining the data bits linearly. The phrase "linear combination" means here single-bit binary arithmetic.
 |  |  |  |
 |  |  |  |
For example, let's consider the specific (3, 1) error correction code described by the following coding table and, more concisely, by the succeeding matrix expression.

or

where

The length-

(in this simple example

) block of data bits is represented by the vector

, and the length-

output block of the channel coder, known as a codeword, by

. The generator matrix

defines all block-oriented linear channel coders.
As we consider other block codes, the simple idea of the decoder taking a majority vote of the received bits won't generalize easily. We need a broader view that takes into account the distance between codewords. A length-
codeword means that the receiver must decide among the

possible datawords to select which of the

codewords was actually transmitted. As shown in Figure 1, we can think of the datawords geometrically. We define the Hamming distance between binary datawords

and

, denoted by

to be the minimum number of bits that must be "flipped" to go from one word to the other. For example, the distance between codewords is 3 bits. In our table of binary arithmetic, we see that adding a 1 corresponds to flipping a bit. Furthermore, subtraction and addition are equivalent. We can express the Hamming distance as

Exercise
Show that adding the error vector col[1,0,...,0] to a codeword flips the codeword's leading bit and leaves the rest unaffected.
In binary arithmetic (see Table), adding 0 to a binary value results in that binary value while adding 1 results in the opposite binary value.
The probability of one bit being flipped anywhere in a codeword is

. The number of errors the channel introduces equals the number of ones in ee; the probability of any particular error vector decreases with the number of errors.
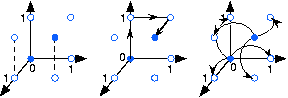
To perform decoding when errors occur, we want to find the codeword (one of the filled circles in Figure 1) that has the highest probability of occurring: the one closest to the one received. Note that if a dataword lies a distance of 1 from two codewords, it is impossible to determine which codeword was actually sent. This criterion means that if any two codewords are two bits apart, then the code cannot correct the channel-induced error. Thus, to have a code that can correct all single-bit errors, codewords must have a minimum separation of three. Our repetition code has this property.
Introducing code bits increases the probability that any bit arrives in error (because bit interval durations decrease). However, using a well-designed error-correcting code corrects bit reception errors. Do we win or lose by using an error-correcting code? The answer is that we can win if the code is well-designed. The (3,1) repetition code demonstrates that we can lose ([link]). To develop good channel coding, we need to develop first a general framework for channel codes and discover what it takes for a code to be maximally efficient: Correct as many errors as possible using the fewest error correction bits as possible (making the efficiency

as large as possible.) We also need a systematic way of finding the codeword closest to any received dataword. A much better code than our (3,1) repetition code is the following (7,4) code.

where the generator matrix is

In this (7,4) code,

of the

possible blocks at the channel decoder correspond to error-free transmission and reception.
Error correction amounts to searching for the codeword

closest to the received block

in terms of the Hamming distance between the two. The error correction capability of a channel code is limited by how close together any two error-free blocks are. Bad codes would produce blocks close together, which would result in ambiguity when assigning a block of data bits to a received block. The quantity to examine, therefore, in designing code error correction codes is the minimum distance between codewords.

To have a channel code that can correct all single-bit errors,

.
Exercise
Suppose we want a channel code to have an error-correction capability of

bits. What must the minimum Hamming distance between codewords

be?

How do we calculate the minimum distance between codewords? Because we have

codewords, the number of possible unique pairs equals

, which can be a large number. Recall that our channel coding procedure is linear, with

. Therefore

. Because

always yields another block of data bits, we find that the difference between any two codewords is another codeword! Thus, to find
we need only compute the number of ones that comprise all non-zero codewords. Finding these codewords is easy once we examine the coder's generator matrix. Note that the columns of

are codewords (why is this?), and that all codewords can be found by all possible pairwise sums of the columns. To find
, we need only count the number of bits in each column and sums of columns. For our example (7, 4),
's first column has three ones, the next one four, and the last two three. Considering sums of column pairs next, note that because the upper portion of
is an identity matrix, the corresponding upper portion of all column sums must have exactly two bits. Because the bottom portion of each column differs from the other columns in at least one place, the bottom portion of a sum of columns must have at least one bit. Triple sums will have at least three bits because the upper portion of
is an identity matrix. Thus, no sum of columns has fewer than three bits, which means that

, and we have a channel coder that can correct all occurrences of one error within a received 77-bit block.
This textbook is open source. Download for free at http://cnx.org/contents/778e36af-4c21-4ef7-9c02-dae860eb7d14@9.72.
Explore CircuitBread


Get the latest tools and tutorials, fresh from the toaster.


